Roteiro para aula de introdução ao banco de dados - Fundatec

Nesse artigo vamos abordar uma introdução para prática de acesso a dados usando Spring Data JPA e um banco de dados mysql.
Em uma das aulas nós refatoramos o código do controlador para separá-lo em camadas. O código está disponível em https://github.com/giovannicandido/aulas-fundatec-spring-rest-introducao/tree/aula-09
Nesse roteiro, vamos refatorar a camada de repository para persistir uma pessoa no banco de dados mysql. Vou assumir que os conceitos principais de bancos de dados já foram abordados (tabelas, selects, inserts, updates, filters, primary key, foreing key e joins)
Após ler esse roteiro você terá:
- Mysql Instalado
- Criado um banco de dados
- Configurado o spring boot para ter suporte ao banco mysql e para conectar no banco criado
- Refatorado o model e o repository de pessoa para ter os dados no banco
- Testado a API
Vamos começar.
Instalando o mysql/mariadb
Há diversas formas de instalar o mysql, a melhor delas seria usando docker pois ele não somente permite usar o mysql mas milhares de outros serviços linux de maneira simples, além de ser a maneira mais profisional para rodar aplicações em ambientes de dev, homologação e produção.
Por isso vou abordar a instalação por ele, no entando vou deixar o link para instalação tradicional nas plataformas Windows e Linux, se a instalação por docker não der certo tente uma delas.
Nos laboratórios das aulas o mysql já vai estar instalado nas máquinas.
Também vou deixar links para se aprofundar no docker com mais tempo pois é um assunto mais extenso que vale apena o estudo, eu vou abordar apenas o necessário para ter o servidor mysql rodando que é o objetivo desse artigo.
Instalando o docker
Primeiramente precisamos do docker, mas o que é o docker?
O docker é um software que gerencia o que chamados de containers. Um conteiner é um processo de sistema isolado por meio de recursos do kernel do Linux. Esse processo possui sua rede virtual, sistema de arquivos isolado e uma imagem.
A imagem é um mecanismo que cria uma "foto" da instalação do software e de suas dependências, a imagem é imutável e formada por camadas que se assemelham a um commit do git.
Quando o docker roda um container, ele baixa a imagem de um registro e cria um processo através dela. A imagem serve então para distribuir o container.
O docker possui um registro central onde diversas imagens podem ser encontradas: o https://hub.docker.com
Um container se assemelha a uma máquina virtual (VM), porém é bem mais leve pois não possui a camada de sistema operacional nem toda emulação de hardware de uma VM.
Para uma definição mais detalhada de container acesse https://esr.rnp.br/administracao-de-sistemas/containers-docker-como-utilizar/
O docker é um dos runtimes para containers (temos também o containerd e o CRI-O) e foi o primeiro a popularizar essa tecnologia e ainda hoje é o mais popular.
É uma tecnologia que nasceu em cima de recursos do kernel do Linux, e um container compartilha o kernel do sistema host principal. No entando é possível instalar em Windows e MacOS através de VM's, mas não se preocupe você não precisa instalar uma máquina virtual com Linux temos uma alternativa muito mais simples.
Instalação do docker no Windows
Acesse: https://www.docker.com/products/docker-desktop/ Baixe o instalador e siga as instruções de instalação. É necessário estar em uma versão atual do Windows 10 ou 11 Deixe marcado a opção "use WSL2 instead of Hyper-V" Após a instalação ele vai iniciar com o sistema e vai estar no dock a direita com um icone que se assemelha a uma baleia. Para testar a instalação abra um terminal (de preferencia windows terminal com powershell) e digite:
docker version
Instalação no Linux
Vai depender da distribuição para o ubuntu siga as instruções em:
https://docs.docker.com/engine/install/ubuntu/
Nota: Use a docker engine e não o docker desktop para linux porque o docker desktop cria um VM, o docker engine roda nativamente e é mais performatico.
Criação do container com Mysql
Com o docker instalado é muito simples rodar um container mysql. Para isso basta um comando:
docker run -d --restart always --name mariadb -p 3306:3306 --env MARIADB_ROOT_PASSWORD=1234 mariadb:latest
Explicando o comando acima:
- docker run: Cria um container novo
- -d : Roda em background, ou seja libera a linha de comando
- --restart always : Diz ao docker que sempre deve iniciar o container com o systema, com isso nos não precisamos fazer um "docker start" para iniciar o container na mão
- --name mariadb : dá um nome para o container, se deixar sem nome depois só podemos referenciar o container por um id gerado automaticamente
- -p 3306:3306 : O container possui uma rede virtual e por padrão essa rede é inacessível para o host, somente entre os containers, então dizemos que a porta 3306 do host é mapeada para porta 3306 do container, assim acessando localhost 3306 acessamos o container
- --env : Configura variáveis de ambiente para o container. Nesse caso criamos uma variável que diz qual a senha de root do mysql
- mariadb:latest : mariadb é o nome da imagem que estamos rodando, latest é a versão. O docker interpreta latest como a ultima versão publicada. Na verdade o que está depois do : é uma tag, com isso podemos instalar versões específicas se quisermos.
Aqui vale uma distinção: O mariadb é o fork opensource do mysql. O mysql foi comprado pela oracle e de lá para cá ele existe em uma versão free e comercial, fizeram um fork dele para mantê-lo opensource.
Essas informações podem ser vistas no docker hub: https://hub.docker.com/_/mariadb
O que vai acontecer:
O docker vai baixar a imagem do mariadb e vai instanciar um container.
Poderemos acessar o mysql como de constume, por exemplo via linha de comando:
mysql -h localhost -u root -p
Uma coisa deve ser dita: O container mariadb armazena os seus dados em um sistema de arquivo interno e temporário. Caso o container seja removido os dados são perdidos. Um container é inicialmente projetado para ser efêmoro, isso é, morrer e não carregar seus dados consigo. A idéia é que ele possa ser instanciado instantaneamente em outra máquina. Abordagens são necessárias para manter o estado (dados) de um container. Uma delas é o mapeamente de volume
Se você fizer um
docker stop mariadb
docker rm mariadb
Todos os dados serão perdidos.
Acessando o mysql
Há diversas formas. Eu uso a nativa do Intellij mas ela é paga. Recomendo o dbeaver pois nele pode-se conectar a diversos tipos de bancos (como o postgresql) e está disponível para todas as plataformas (Linux, Mac e Windows)
Baixe e instale-o em: https://dbeaver.io/download/
Escolha o mariadb como base de dados:
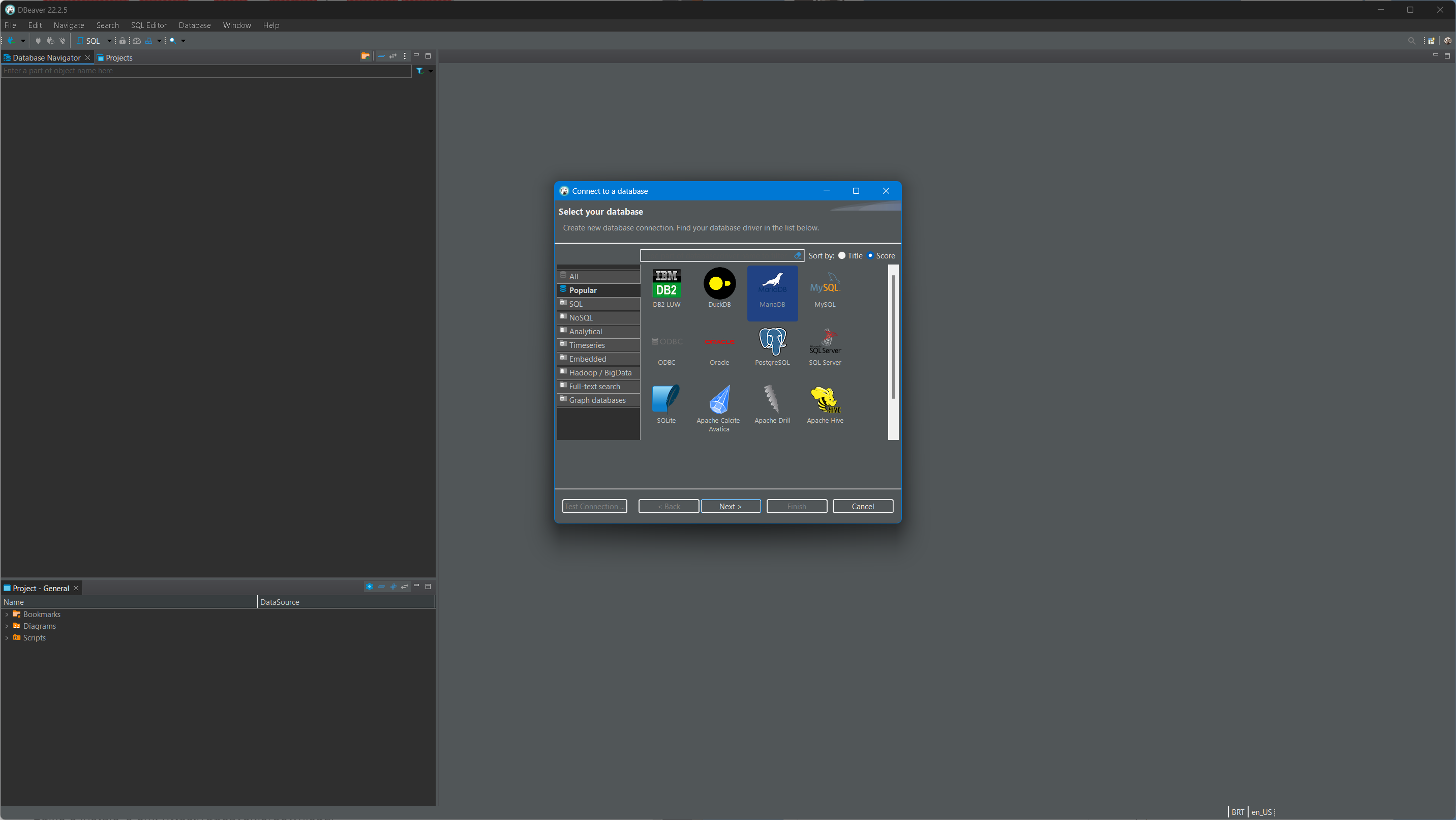
Preencha os dados de host (localhost) porta (3306) usuário (root) e senha (1234)
Expanda o servidor, clique com o botão direito em cima de Databases e crie uma nova base de dados com nome de lpII
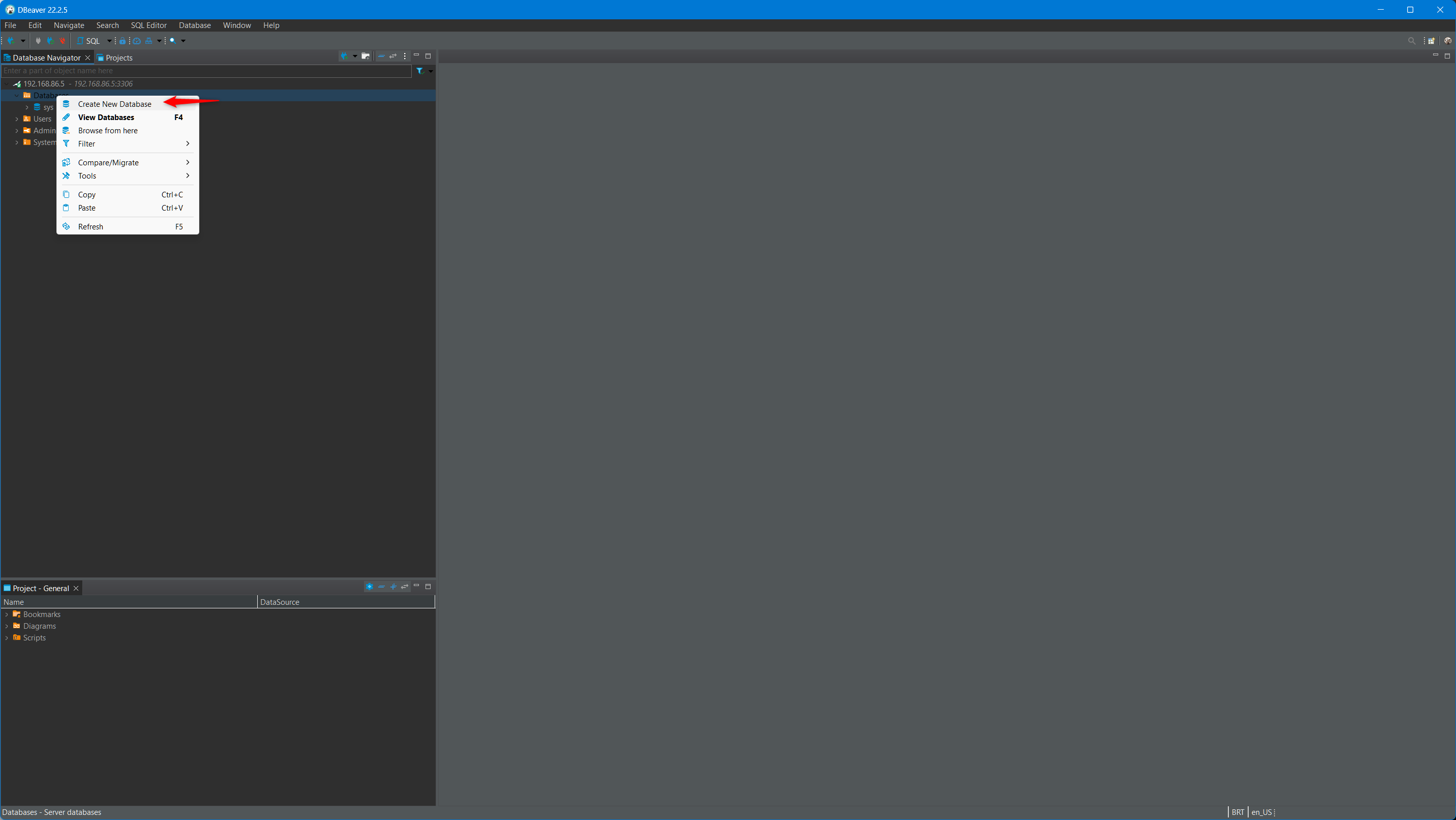
A partir daqui você pode criar tabelas, fazer inserts entre outros mas vamos configurar o Spring para criar as tabelas para agente.
Refatorando a aplicação para usar banco de dados
Configurando a Aplicação para Conectar ao Banco
Vamos configurar a aplicação para usar o spring data jpa como framework de acesso a dados.
Edite o arquivo pom.xml na raiz do projeto e adicione as seguintes dependencias:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<version>3.1.0</version>
</dependency>
O starter JPA é a depedencia para trabalhar com dados. O mariadb-java-client é o driver do banco que vamos conectar.
Dê um refresh no maven do projeto
Agora edite o arquivo src/main/resources/application.properties
Configure o spring para conectar no banco com as propriedades:
spring.datasource.url=jdbc:mariadb://localhost/lpII
spring.datasource.username=root
spring.datasource.password=1234
Rode o projeto. Se o spring não apresentar erros a conexão com o banco foi estabelecida. Exemplo:
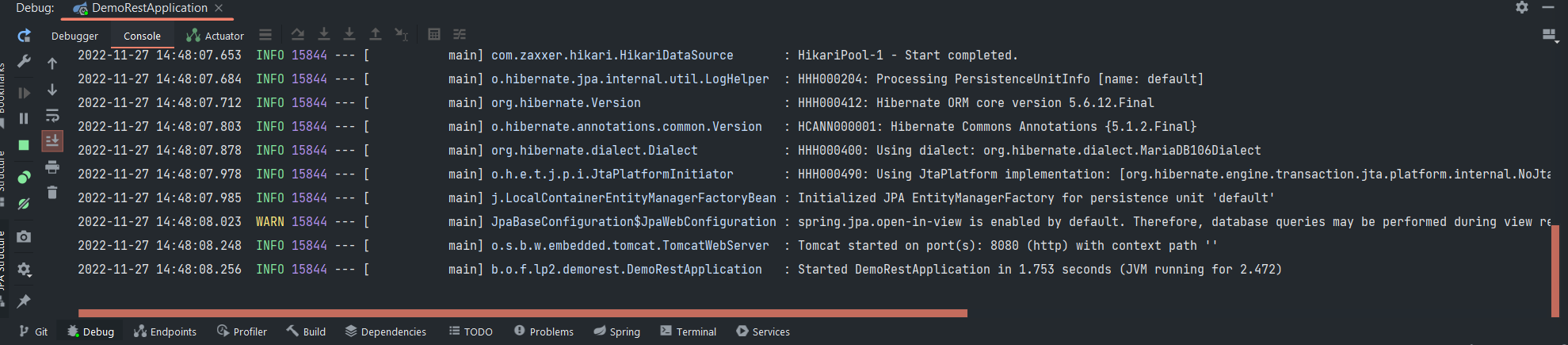
Vamos configurar o hibernate JPA para gerar as tabelas com base nos modelos para agente: adicione a linha abaixo no application.properties
spring.jpa.hibernate.ddl-auto=update
Atualizando o modelo de dados
Agora precisamos de uma tabela. Edite o arquivo model/Pessoa e adicione as minimas anotações:
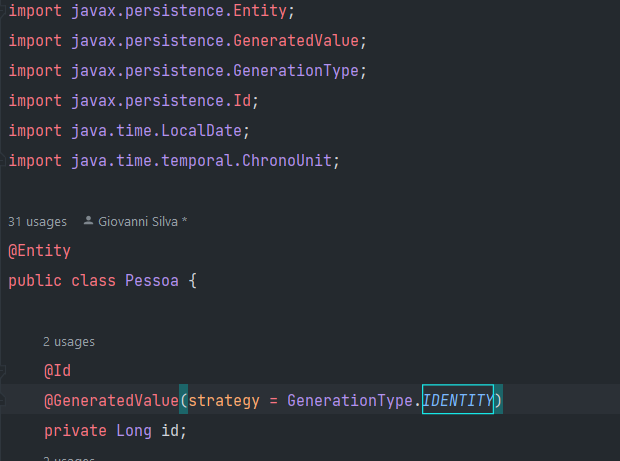
O restante da classe deixe como está. Rode o projeto novamente e veja se uma tabela pessoa foi criada
Explicando as anotações:
- @ Entity - Colocada na classe diz que ela é uma entidade, ou seja, uma tabela no banco de dados
- @ Id - Toda entidade deve possui um ID que a identifica unicamente na tabela (primary key), O id então será a propriedade id do tipo Long @ GeneratedValue - Instrui o hibernate a gerar essa propriedade usando alguma estratégia (auto increment, sequence, etc). No caso o strategy é IDENTITY que significa que o banco vai gerar para agente um numero incremental.
Para o restante das propriedades o hibernate vai assumir o padrão.
- Para cada propriedade ele vai criar uma coluna correspondente, com o tipo correspondente. Exemplo: String é mapeado para varchar(255) e LocalDate é mapeado para date
- O nome da coluna é o nome da propriedade
Podemos sobrescrever os default com outras anotações. Por exemplo para alterar o tamanho de uma coluna ou o seu nome:
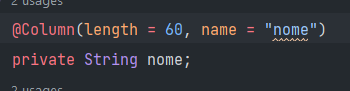
A propriedade spring.data.hibernate.ddl-auto=update tentará atualizar o banco, no entando há casos em que ela não consegue. Altere temporariamente o valor para create-drop reinicie o spring e a tabela será criada novamente com a coluna nome em varchar(60)
Modificando o repository
Vamos alterar o repository de pessoa para que as operações sejam feitas por ele. Temos duas opções:
- Criar um repository com a API do spring data e quebrar o contrato com o service, fazendo com que tenhamos que refatorar todos os metodos do service
- Implementar uma interface com o contrato entre service e repository
Vamos fazer o segundo por ser mais elaborado. Mas note que em um projeto que começe com spring data isso não seria necessário pois já se utilizaria as API dos mesmo
Renomeie a classe PessoaRepository para PessoaRepositoryImpl
No intellij clique com o botão direito em qualquer metodo da classe e vá em refactor > extract interface.
De o nome da interface de PessoaRepository
Selecione todos os metodos publicos
Crie e quando for perguntado se deseja analisar e fazer o replace das partes que usam PessoaRepositoryImpl para PessoaRepository diga sim.
Verifique se a classe PessoaService agora depende de PessoaRepository (interface) Verifique se a classe teste está ok. Atualmente ela não faz nada então os testes devem compilar e passar (vamos abordar testes de spring em outro momento)
Crie uma nova interface PessoaRepositorySpring
Extenda de JpaRepository e passe os generic Pessoa e Long:
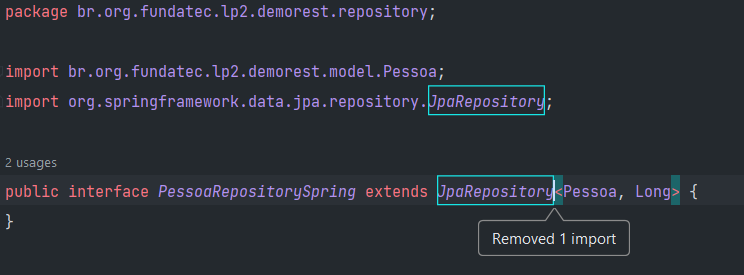
Esse seria um repository padrão do spring. Explicando:
Ao estender de JpaRepository herdamos todos os metodos necessários para se trabalhar com o banco. O spring irá injetar essa classe e criar a implementação para agente. O primeiro generic, é o tipo de Entidade que o repository trabalha, no caso Pessoa, o segundo generic é o tipo do ID que pessoa tem, no caso Long
Temos duas opções para não quebrar a API.
A primeira opção seria criar uma nova classe de implementação de PessoaRepository e usar o PessoaRepositorySpring dentro dela:
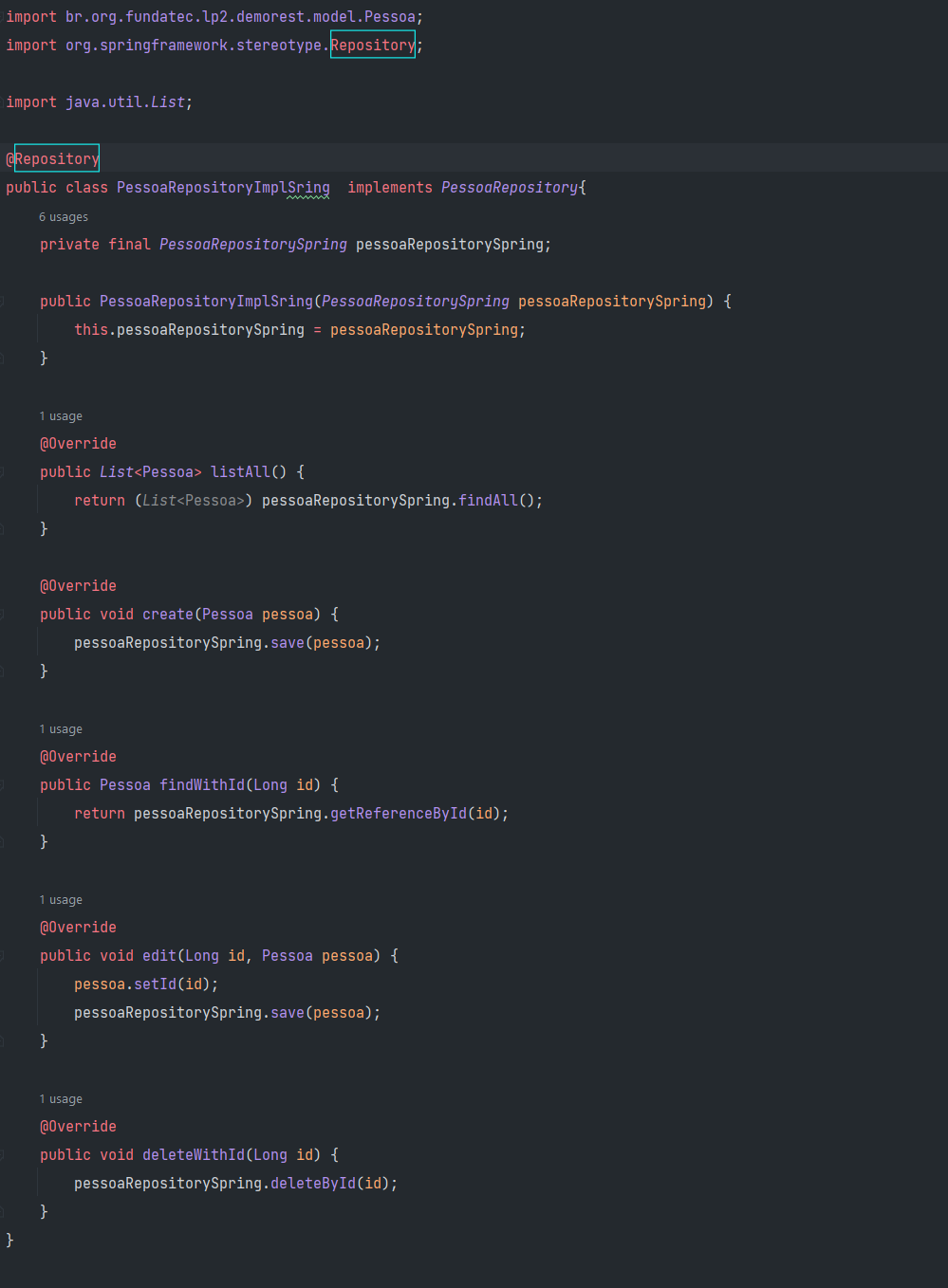
Mas isso gera uma classe a mais sem necessidade. A segunda opção é que podemos fazer com que a propria interface PessoaRepositorySpring implemente os metodos usando o recurso de default implementation das interfaces java:
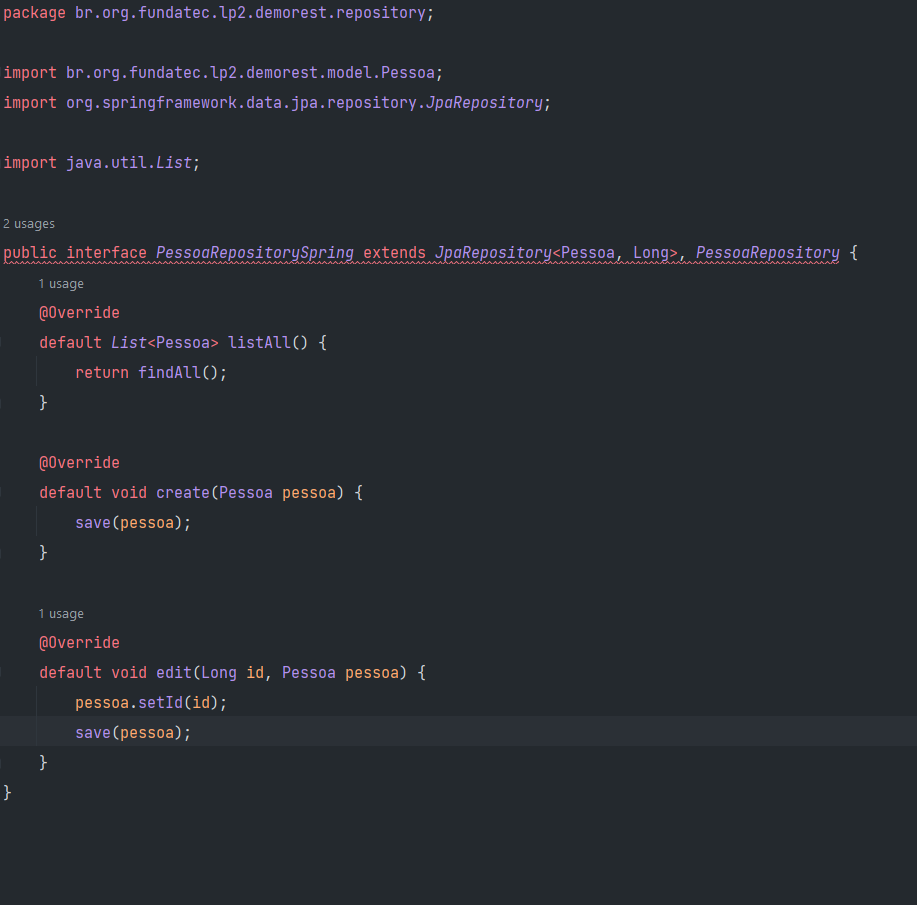
Porém há um problema. O método findById da interface PessoaRepository não é compativel e não pode ser sobrescrito pelo metodo findById de JpaRepository fazendo com que haja um problema de compilação. Para isso a melhor forma é fazer com que o retorno de PessoaRepository seja compatível com ele, ou renomear o método.
Vamos renomear o metodo para que não quebre o retorno esperado pelo Service (lembre-se estamos fazendo isso tudo para não refatorar o service ou seja não alterar a camada superior com uma implementação nova da camada repository)
Faça um refactoring renomentado PessoaRepository findById para findWithId e adicione a implementação em PessoaRepositorySpring:
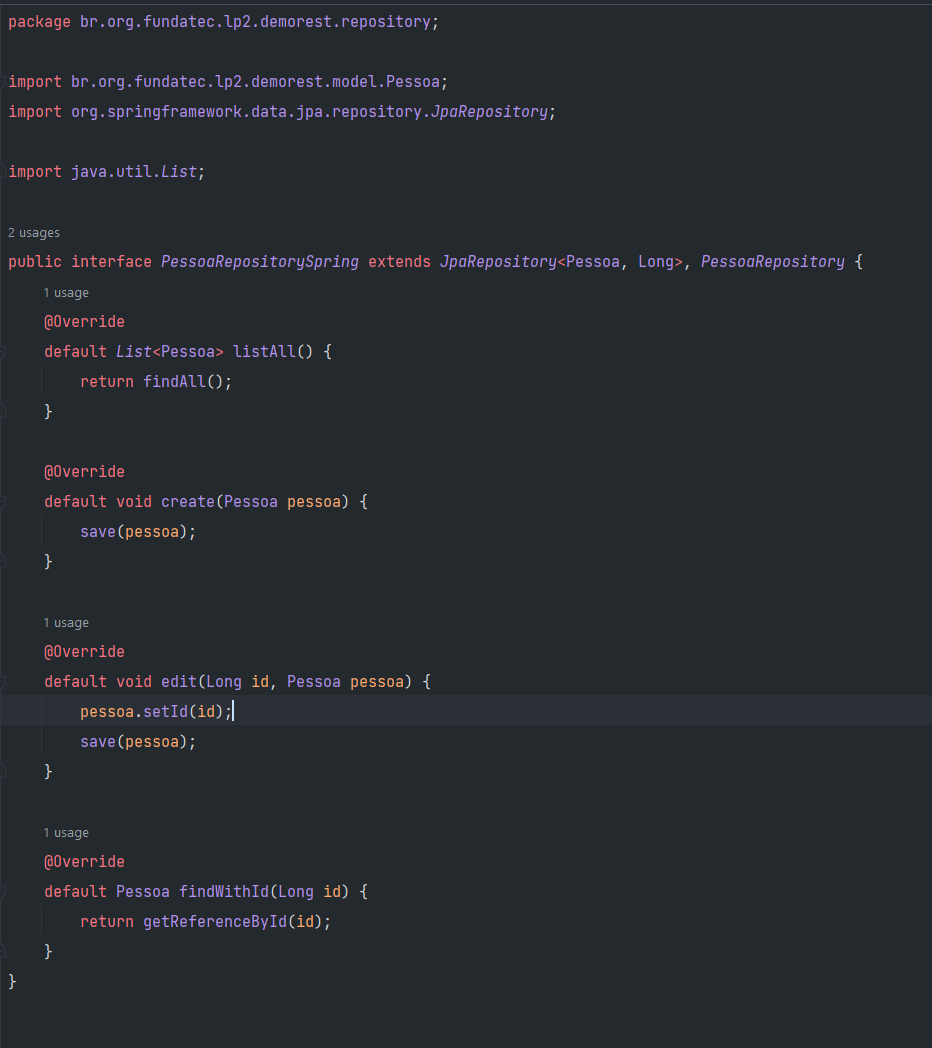
Tente rodar a aplicação.
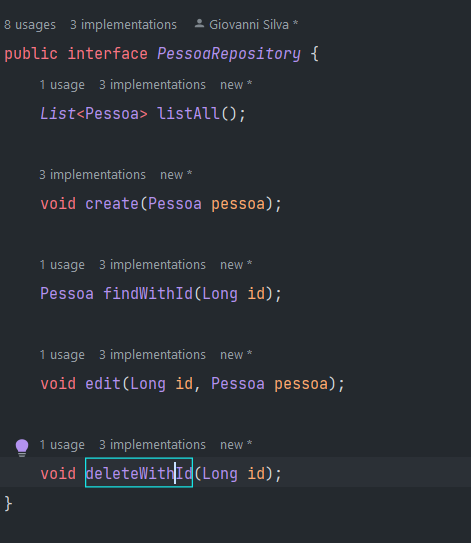
Temos um erro de compilação que diz: "reference to deleteById is ambiguous" Isso acontece porque tanto o PessoaRepositorySpring, quanto PessoaRepository declaram deleteById e PessoaRepositorySpring extende PessoaRepository.
Para resolver renomeie o metodo em PessoaRepository e implemente em PessoaRepositorySpring:
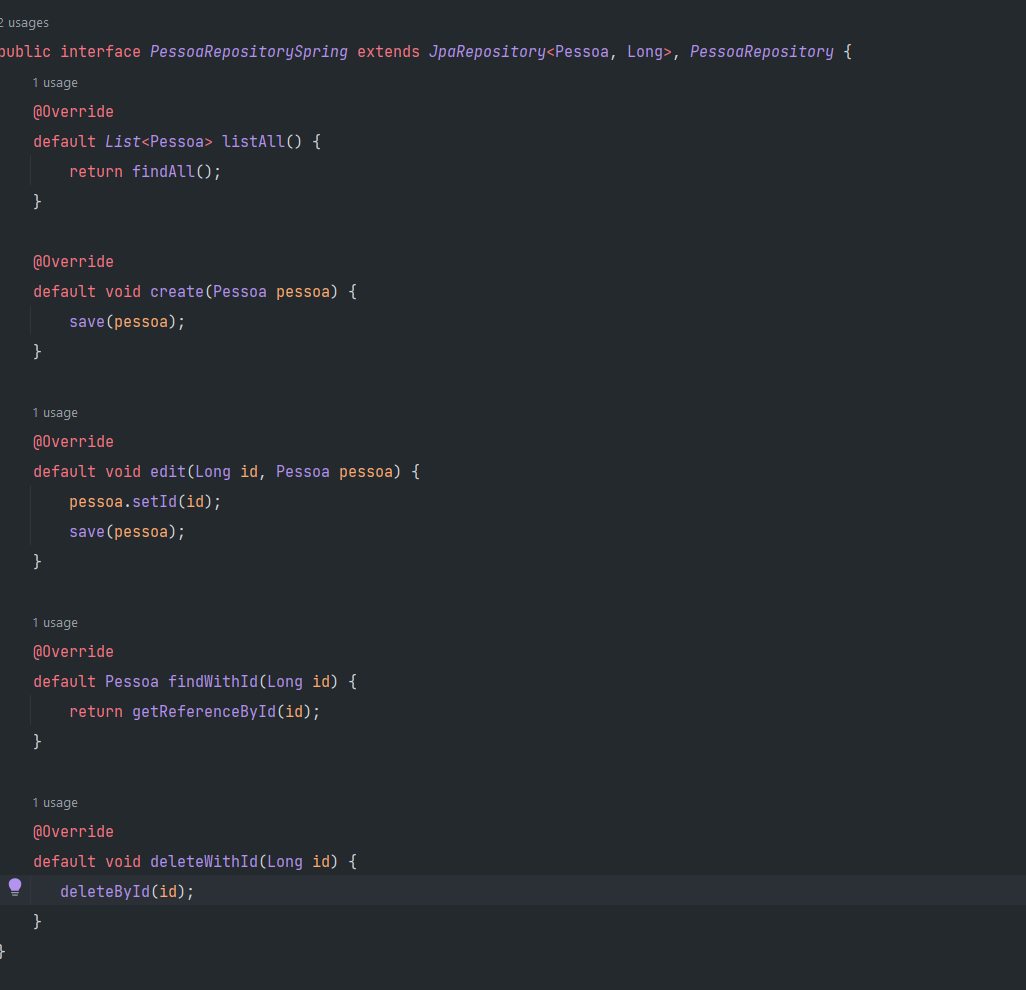
Tente rodar a aplicação:
Spring vai falhar com uma mensagem:
Parameter 0 of constructor in br.org.fundatec.lp2.demorest.service.PessoaService required a single bean, but 3 were found:
- pessoaRepositoryImpl: defined in file [C:\Users\giova\Projects\personal\aulas\fundatec\aula09\demo-rest\target\classes\br\org\fundatec\lp2\demorest\repository\PessoaRepositoryImpl.class]
- pessoaRepositoryImplSring: defined in file [C:\Users\giova\Projects\personal\aulas\fundatec\aula09\demo-rest\target\classes\br\org\fundatec\lp2\demorest\repository\PessoaRepositoryImplSring.class]
- pessoaRepositorySpring: defined in br.org.fundatec.lp2.demorest.repository.PessoaRepositorySpring defined in @EnableJpaRepositories declared on JpaRepositoriesRegistrar.EnableJpaRepositoriesConfiguration
Isso acontece porque agora temos 3 implementação possíveis para PessoaRepository e o spring não sabe qual injetar.
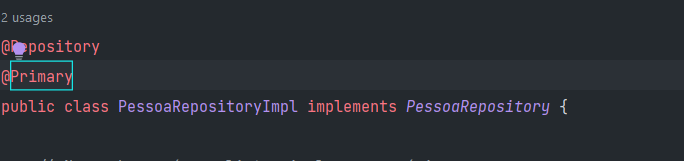
A forma mais simples de resolver isso é setar uma das implementações como @Primary isso vai fazer com que o spring use-a.
Primeiramente vamos setar como @Primary nossa antiga implementação de repository em memória com listas:
Reinicie e teste inserir alguma coisa usando o Insomnia REST
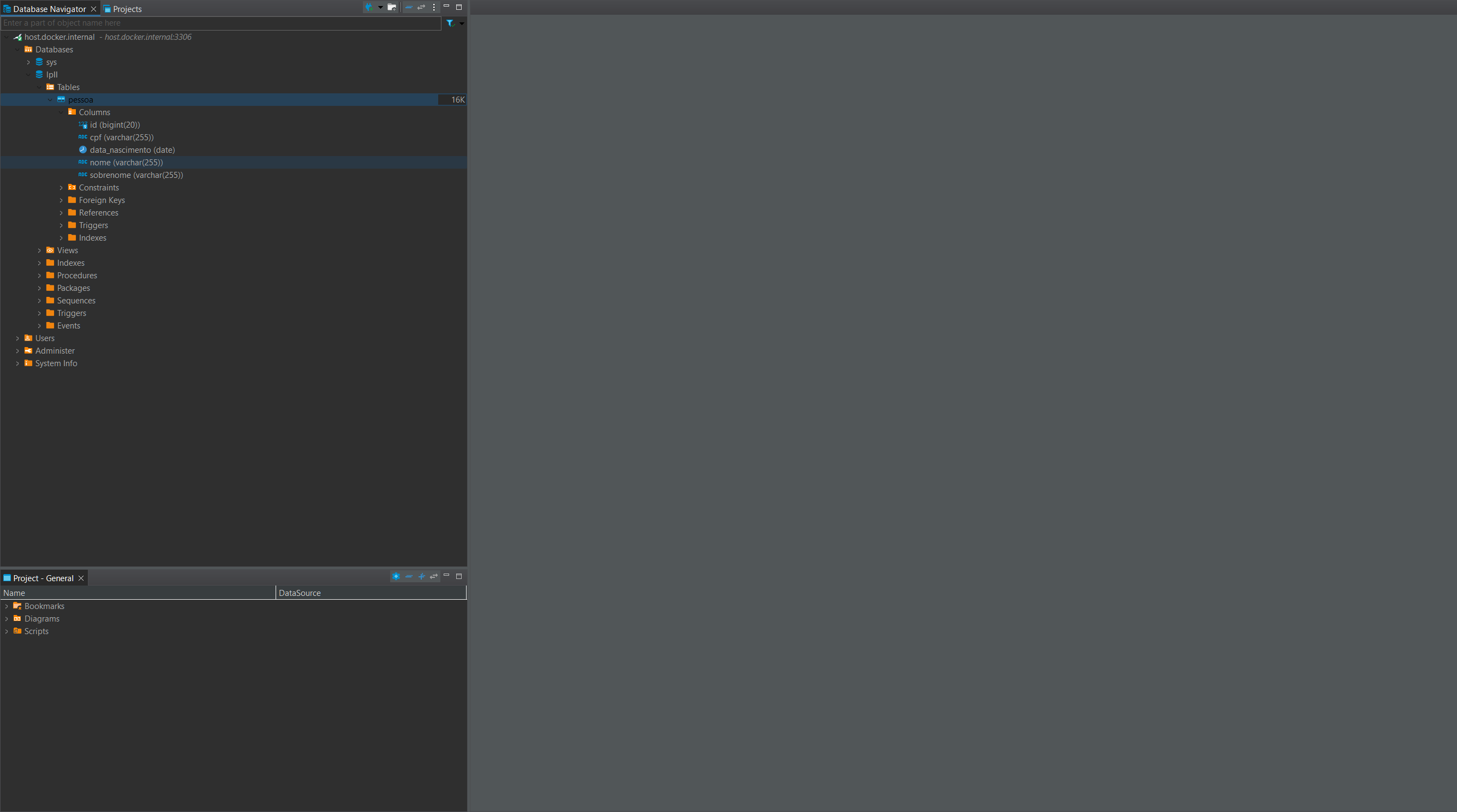
Verifique que a API retorna itens usando o GET pessoas, mas no dbeaver não vai haver registros
No dbeaver vá em Sql Editor > Open SQL Console
Digite a query:
select * from pessoa;
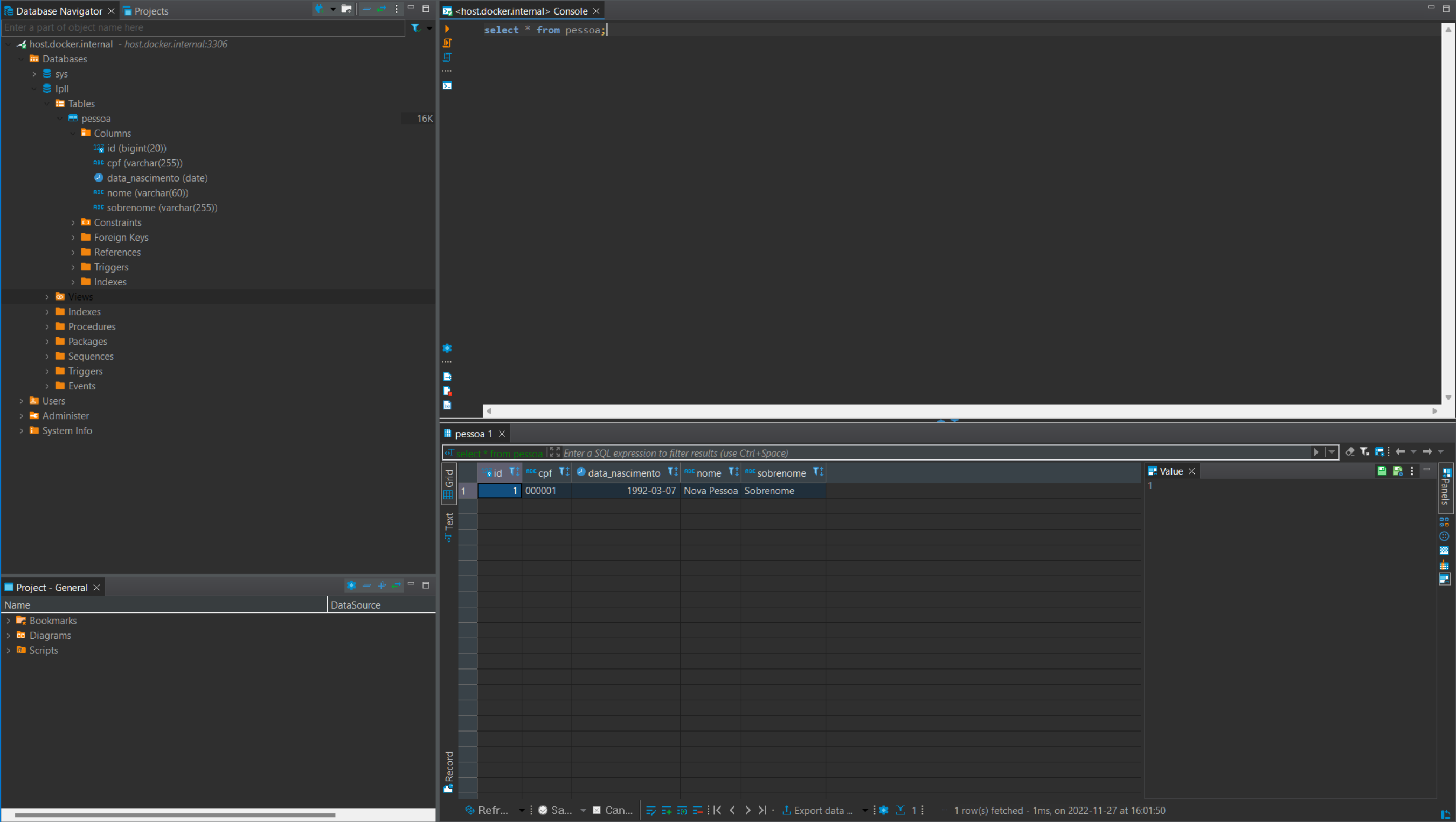
Agora troque a implementação para uma das classes de repository que usam o Spring JPA (PessoaRepositoryImplSpring ou PessoaRepositorySpring), adicionando o @Primary em outra classe (não se esqueça de removê-lo de PessoaRepositoryImpl)
Repita o teste e rode a query novamente. Deve encontrar os registros:
Conclusão
Nos refatoramos o repository para salvar no banco de dados os dados de pessoa. No final acabamos com 5 classes no repository:
- PessoaIndex - Auxiliar para trabalhar com a lista em memória
- PessoaRepository - Nossa interface principal da qual PessoaService depende
- PessoaRepositorySpring - Interface que usa o spring para ir no banco de dados. Essa é a classe principal para conexão com o banco
- PessoaRepositoryImpl - Nossa implementação de lista em memória
- PessoaRepositoryImplSpring - Uma implementação intermediaria como alternativa para manter a compatibilidade com a interface do service.
Na próxima aula vamos criar um novo endpoint, ele nele vamos ter apenas uma interface para repository, a interface principal do spring.
O código para essa aula está disponível em: https://github.com/giovannicandido/aulas-fundatec-spring-rest-introducao/tree/aula-11
Referências
Seguem alguns links para estudarem os assuntos:
Instalação do mariadb:
https://mariadb.org/download
Documentação sobre Docker:
https://docs.docker.com/get-started/ https://blog.geekhunter.com.br/docker-na-pratica-como-construir-uma-aplicacao/
Documentação Spring Data e JPA
https://www.baeldung.com/the-persistence-layer-with-spring-data-jpa https://www.treinaweb.com.br/blog/iniciando-com-spring-data-jpa
https://www.alura.com.br/apostila-java-web/uma-introducao-pratica-ao-jpa-com-hibernate https://www.devmedia.com.br/jpa-e-hibernate-acessando-dados-em-aplicacoes-java/32711 Vários Tutoriais: https://www.javaguides.net/p/jpa-tutorial-java-persistence-api.html
Apresentação sobre JPA https://1drv.ms/p/s!AoHvV-Rb6N9Qg9YV8286A29SOLJnbw?e=51hdJh